If you’ve upgraded to the October 2020 release of Power BI Server, you might be seeing the following error when you refresh some of your reports:
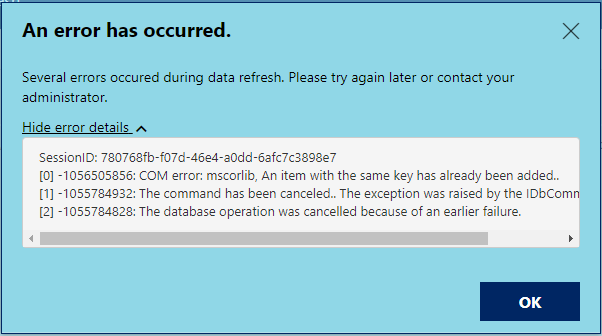
This error appeared when we install the November 18th patch for Power BI Server (15.0.1104.264) and wasn’t present in the original October 2020 release. The especially frustrating part was that reports refreshed just fine in the Power BI Desktop client, and the issue only appeared after publishing the report up to Power BI Server, making it much more difficult to troubleshoot.
However, the resolution ended up being pretty straightforward – there are two different ways to define a connection to a SQL Server database, and if you use both methods in the same data model and then merge the results, Power BI Server has a problem with it (and Power BI Desktop does not). To correct this issue, you need to pick a method and ensure that all the SQL Server connections in your data model use this single method to connect to the database.
One method is used when you specify a database server, but don’t specify a database:
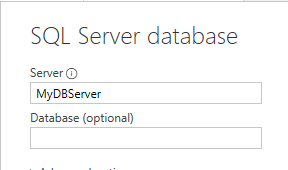
This results in the following M query, with the connection taking up the first two lines (one for server, one for database):
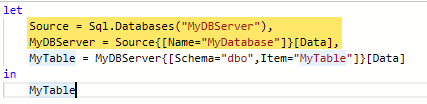
If you specify the database in the connection window instead, it merges the connection statement onto a single line and uses Sql.Database (singular) instead of Sql.Databases (plural). Since you’re required to specify a database name when you provide a SQL query, so a custom query always uses this one-line method to connect:
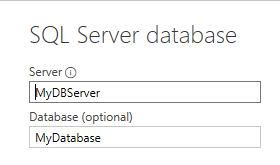
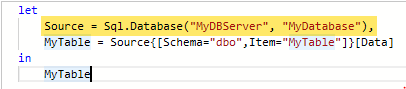
Regardless of whether you enter the database name (and have the one-line connection method) or don’t enter a database (and use the two-line method), it looks exactly the same in the step window in Power Query:
I’d recommend using method two for all your connections, as that’s what’s needed to run a specific SQL query – if any of your data sources and query-based and not just selecting a table, you’ll have to use this approach.
I hope this helps somebody else! While I’d love it if Power BI Server avoided errors like this one, I’d also really appreciate it if Power BI Server and Desktop used the same code for shared functionality so that you can be aware of issues before you publish your reports and they fail to refresh.
This took some frustration to resolve and I’m thankful for finally finding the resolution to this issue through a bug report that “JeanMartinL” had filed: https://community.powerbi.com/t5/Issues/BUG-Report-Server-refresh-fails-if-data-source-are-created/idi-p/1528954. Whoever you are, thank you!
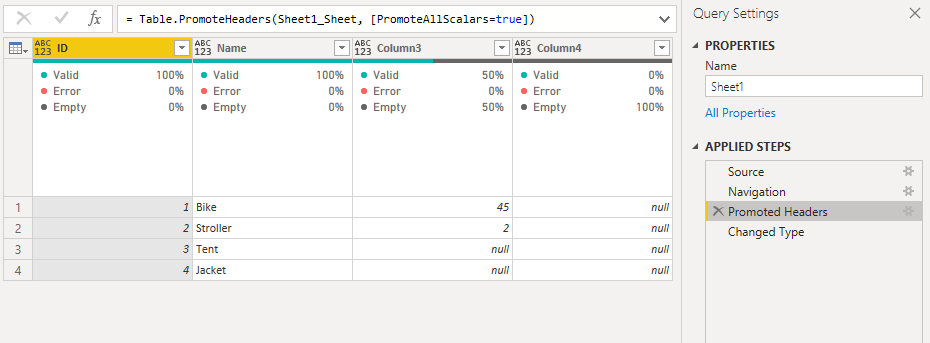




 If you double-click on the “Data Files” query with the error, you can see that it loaded the data from the first file, but nothing from the others:
If you double-click on the “Data Files” query with the error, you can see that it loaded the data from the first file, but nothing from the others:

 Replace the highlighted text with “Item=Source{0}[Item]” so that it looks like this:
Replace the highlighted text with “Item=Source{0}[Item]” so that it looks like this: (The “0” refers to the first sheet – if you want the second sheet, you’d use “1” and so on). If you’re using an XLS file rather than an XLSX file, the text looks a little bit different: “Name=Source{0}[Name]“. The XLSX file has a Name field as well, but it can vary from the “Item” column.
(The “0” refers to the first sheet – if you want the second sheet, you’d use “1” and so on). If you’re using an XLS file rather than an XLSX file, the text looks a little bit different: “Name=Source{0}[Name]“. The XLSX file has a Name field as well, but it can vary from the “Item” column.





