When setting up an ODBC connection to a Hive server, you sometimes need to change your queue name – if the default queue you’re assigned doesn’t work for what you need to do, here’s how you change it in the DSN settings. You can use this process to set any other “Server Side Property” (or SSP) that your server requires.
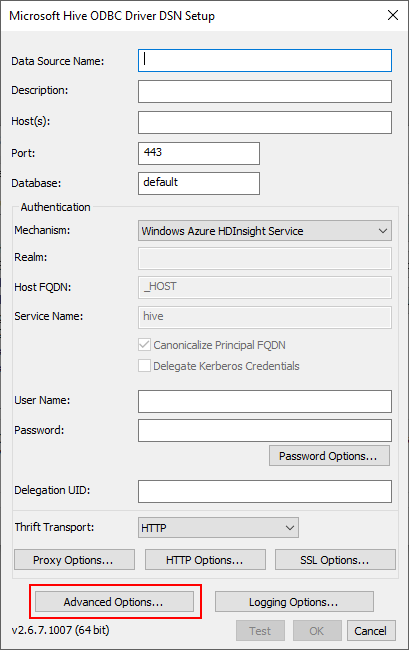
Open your DSN settings window for the data source where you want to set to queue name, and click “Advanced Options…” in the lower left:
The DSN Settings window that shows the common settings. This window is currently showing the default settings for the ODBC driver and your settings may be different.
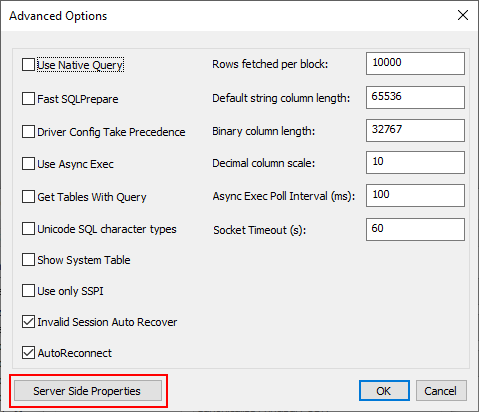
Click “Server Side Properties” in the lower-left corner of the Advanced Options window:
The “Advanced Settings” window with default settings.
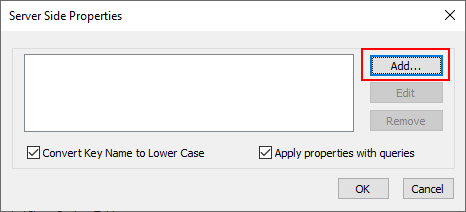
In the Properties window, click “Add..” on the right side to create a new property:
The window where you add new server side properties.
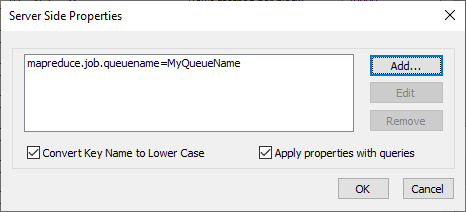
Add any properties required by your Hive instance, including the mapreduce queue name if needed. You may have to ask your administrator what the name of this property is – some servers use “mapreduce.job.queuename” by default, and one server I use has this defined as “mapred.job.queue.name“, so you’ll need to confirm your server’s value. Once you know what it is, create it and click OK, and then it should look like this:
Show the results of the server side property for queue name once it’s set.
That’s it! Go ahead and click “OK” and save the data source name settings, then you should be good to go!
If you have the need to use different queues for different purposes (or any other settings change based on your work), you can create multiple versions of your ODBC DSN and connect to whichever one is appropriate for the work you’re currently doing.
If you’re looking for a Hive driver, I’m showing the Microsoft Hive ODBC driver in this walkthrough and I’ve had a great experience with it (and it’s free – most other drivers at least require you to give your contact information, but this one doesn’t). There are other drivers you can use, and each has a place you can set any SSP that you need for your connection – please check the documentation for your specific driver if you need details.
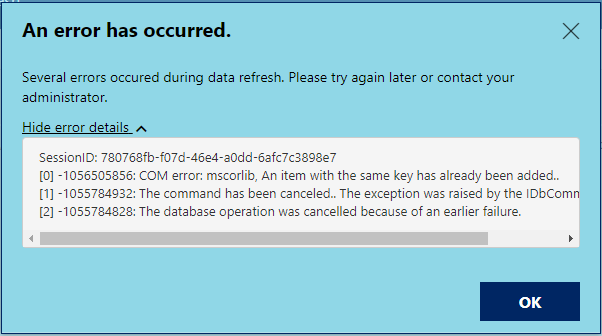
If you’ve upgraded to the October 2020 release of Power BI Server, you might be seeing the following error when you refresh some of your reports:
[0] -1056505856: COM error: mscorlib, An item with the same key has already been added..
This error appeared when we install the November 18th patch for Power BI Server (15.0.1104.264) and wasn’t present in the original October 2020 release. The especially frustrating part was that reports refreshed just fine in the Power BI Desktop client, and the issue only appeared after publishing the report up to Power BI Server, making it much more difficult to troubleshoot.
However, the resolution ended up being pretty straightforward – there are two different ways to define a connection to a SQL Server database, and if you use both methods in the same data model and then merge the results, Power BI Server has a problem with it (and Power BI Desktop does not). To correct this issue, you need to pick a method and ensure that all the SQL Server connections in your data model use this single method to connect to the database.
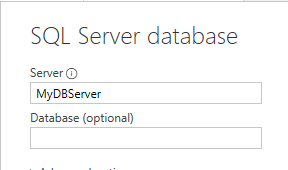
One method is used when you specify a database server, but don’t specify a database:
SQL Server connection with no database specified
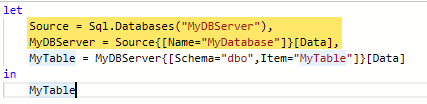
This results in the following M query, with the connection taking up the first two lines (one for server, one for database):
M-query showing two-line database connection
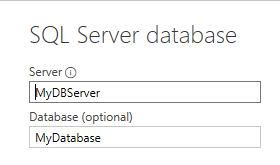
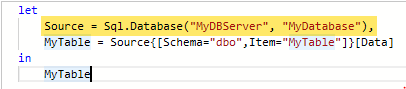
If you specify the database in the connection window instead, it merges the connection statement onto a single line and uses Sql.Database (singular) instead of Sql.Databases (plural). Since you’re required to specify a database name when you provide a SQL query, so a custom query always uses this one-line method to connect:
Connection window showing database nameM-query database connection merged into a single line
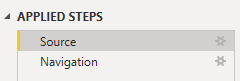
Regardless of whether you enter the database name (and have the one-line connection method) or don’t enter a database (and use the two-line method), it looks exactly the same in the step window in Power Query:
“Source” is the database connection, whether it’s one or two lines. Navigation is the step that specifies the table/view you’re connecting to, and is the “MyTable” step in the examples above.
I’d recommend using method two for all your connections, as that’s what’s needed to run a specific SQL query – if any of your data sources and query-based and not just selecting a table, you’ll have to use this approach.
I hope this helps somebody else! While I’d love it if Power BI Server avoided errors like this one, I’d also really appreciate it if Power BI Server and Desktop used the same code for shared functionality so that you can be aware of issues before you publish your reports and they fail to refresh.
Avoid IT “Involvement Entitlement” by being a partner with the business, not a gatekeeper – if they’re not coming to you for help, don’t require it, but instead ask yourself why not and fix that.
You’re in the IT department, and you have some pretty solid processes in place – project request forms and approval committees, change approval and management, and some kind of steering committee. Instead of everything lining up nicely, though, you’re getting business units going around the process, building their own applications, writing their own code, and doing it without IT approval. With such a great funnel to go through and everything so neatly defined and documented, why would the business do that?
What is “Involvement Entitlement”?
This Programmers.StackExchange question is a great summary of this, and there’s a general feeling throughout many of the answers that I’ll call “Involvement Entitlement.” In summary, I’d define it this way:
All use of technology must be in a manner explicitly approved by IT, and any custom solutions in place must be written by a developer in the IT department. Any use of technology in a way not explicitly cleared by IT is forbidden.
This attitude can manifest itself in many different ways:
A policy requiring IT approval for any software
Locking down computers so nothing unapproved can be installed
Allowing custom development, but requiring that it clear some bar of “development” or “infosec” approval that’s never actually met in practice or is so complicated that it’s never actually attempted
Custom applications or processes being “allowed”, but setting up requirements with learning curves so high that it’s not feasible for anybody outside IT to meet them (for example, “all applications must be developed in C++” or “every process must have high-availability and load-balancing with automatic no-touch failover to multiple data centers”), when there’s no technical reasons for these requirements
The problem is that these policies don’t actually prevent custom solutions; they just prevent IT from being involved in (or often even finding out about) the things that are being developed. The business doesn’t want to skirt the process or avoid IT, but they do want something very simple – for their jobs to be easier. When the business builds a custom solution like an Excel macro that takes a workbook and uses keypress automation to type a long list of transactions into the accounting software, or small .NET desktop app that generates PDFs for customer paperwork for bankruptcy processing and emails it to the relevant state authority, they’re doing it for one reason – it’s easier than doing it the old way. If they’re not involving IT, it’s for the same reason – it’s easier that way.
What’s really going on?
When you stumble across one of these processes that didn’t go through IT, ask yourself the following two things:
What are they trying to accomplish by developing something themselves?
Why is the business going around the IT processes?
If you don’t like all the custom development that’s going on, forbidding it is mistaking a symptom for the problem – you should instead be asking why they’re going around IT, not just telling them it’s not allowed. Remember that you (IT) exist to help make their job easier, not more complicated. Sometime the value of IT comes in the form of ensuring that applications are fault tolerant or high availability, or in the form of ensuring an application can be supported once the lone developer that built it leaves the company. At the end of the day, you’re in the solution business, and if you and your processes aren’t enabling the business to work better, you’re not adding value.
But here’s something to remember: Every custom application that’s been developed outside of IT corresponds to a need that’s not being met by IT. There may be a good reason they’re not met – not a priority in the company, very specialized problem, not as good as other options, custom language your IT people don’t know, etc – and the lack of IT involvement may be legitimate, but these solutions were created because some department had a need that IT couldn’t (or wouldn’t) satisfy.
IT can still help – be a partner, not gatekeeper
Try to help them solve their problems, and if you don’t have the time or resources, let them solve them on their own. Mandating some language that has a steep learning curve, with the sole purpose of keeping people out of your business, only serves to enhance the elitist attitude most business users perceive IT to have. In the end, that kind of elite attitude only leads to more of the same problem, as users are afraid to approach IT for fear that they’ll either be told “no” outright or that it will add extra effort without adding any value.
There’s no reason I’d forbid this sort of development, within reason – it eases up constraints on shared resources (mainly IT), and allows each group to empower themselves to solve their own problems (as people versed in advanced Excel are pretty common, since this is a common problem, most departments have at least one).
However, you also shouldn’t be expected to solve any problems that arise from these applications, or support them after the original developer leaves the company. As some of the comments in that original post mention, this doesn’t stop the big boss from demanding that you support it, but if you keep a feel out for the kinds of custom applications or processes out there, you can get a feel for when something becomes critical and you might need to get involved to bring it “in-house.” Also, if something is connecting to and modifying systems that are under IT control, then IT should be involved, if only to ensure the security and integrity of their central systems – however, if it’s something confined to a user’s desktop, why feel the need to forbid it?
Postscript – don’t let perfect stand in the way of done
When I said I started this post 7 years ago, I mean it – it’s a classic case of not knowing exactly what perfect looked like, so I let it stand in the way of done. Go find something you’re not sure how to finish and figure out what keeps you from getting it done – and then deliver 🙂 A moderately good idea delivered is worth 100x as much as an incredible idea stuck in your head!
A script to generate failed report refresh alerts in Power BI Server and can be scheduled with SQL Agent.
Power BI Server has it’s use cases, but it also has some gaps where it falls short of the functionality in the Power BI Service (app.PowerBI.com), but one of the major gaps is that it doesn’t notify anybody when a report refresh fails. Report owners are left either reviewing the reports every time they’re scheduled to ensure the data is refreshed, creating a report that shows refresh status (and hoping it actually refreshes itself), or implementing their own homebrew notification solution.
I opted for #3 – creating a custom notification process – and I want to share it with anybody else that’s wondering how to set up notifications for their own internal Power BI Server instance. If you just want the script, jump to the end for the link and variable instructions.
The process has a few high-level parts:
Query for failed report refreshes. Check the report catalog and refresh history to find reports where the last refresh attempt failed within the monitoring window. If a report has already been refreshed again and succeeded, or is currently being refreshed, I chose not to alert on these – this meant somebody was already on it, and we wanted to see reports that needed attention and were currently failed, not the actual failures themselves.
Create the email notification text. This is a multi-step process that inserts a header, builds a table with details on the reports, and then a footer with instructions and additional details.
Actually send the email. Don’t forget to do this part 🙂 We’ll use DBMail to send it.
SQL Agent job that runs the notification code. This is the recurring schedule that checks for failures. We chose to run it every 5 minutes, so that’s what I have it set up for below (it can be customized as needed for any interval).
CAVEAT BEFORE WE START: We’ll be querying the PBI Report Server database, which could change at any time and is totally unsupported. I’ve never seen any issues caused by it and I’ve never had a table/view change from under code I’ve written to do this, but you’ve been warned. However, we’re only reading – don’t make any changes or write to this database or you could break your PBIRS installation. If you want to learn more about this in general, check out this write-up.
Query for failed report refreshes
We’ll start by all the last successful refreshes for our reports. The process doesn’t actively use this, but it does keep it so that reports that have never been refreshed or where they’ve not been refreshed successfully for X time can be called out in the future:
SELECT [SubscriptionID]
,max([EndTime]) as LastSuccessTime
FROM [YourPBIRSDatabase].[dbo].[SubscriptionHistory]
WHERE Status = 0 -- Success ("Completed Data Refresh")
GROUP BY SubscriptionID
The [SubscriptionHistory] table contains all the records for all scheduled refreshes, regardless of success or failure. In this case, we’re filtering for “Status = 0”, which is success – other numbers are error codes.
To grab a list of all the reports and their refresh status, we’ll use two more tables: [Catalog] (which contains a list of all the reports) and [Subscriptions] (which contains the scheduled refresh jobs). Where [SubscriptionHistory] is the log of all the job executions, [Subscriptions] contains a list of every scheduled refresh that’s set up. One of the nice things about this table is that it also contains details about the current state of the schedule – if the last run was successful or a failure, and details on the last error if there was one.
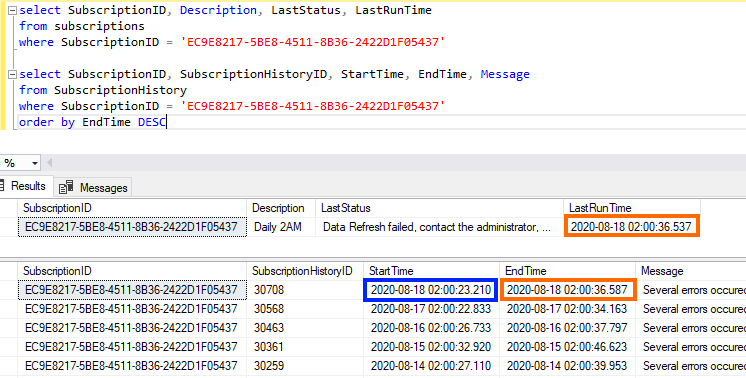
[Subscriptions] also contains a column called [LastRunTime] with a timestamp when the schedule was last run. What’s handy here is that it’s a timestamp for the last STATUS of the schedule, not the time the last refresh started. Because of that, it will contain the timestamp of the end of execution in case of a failure. Here’s how they link together (the boxes in orange match, or match close enough to show that it’s end time and not start time):
When we join those together, here’s what we get (you’ll start to see some variables here – there script has a large block at the top where you can use customize the script behavior):
select LEFT(c.Path, LEN(c.Path) - LEN(c.Name)) as Path,
c.Name,
@URLRootDataRefresh + Path as DataRefreshURL,
s.Description, s.LastStatus, LastRunTime, ls.LastSuccessTime
into #workingtable
from [dbo].[Subscriptions] s
join dbo.[Catalog] c
on s.Report_OID = c.ItemID
where s.LastStatus not in ('Completed Data Refresh', 'New Scheduled Refresh Plan', 'Refreshing Data')
and c.path not like @IgnorePath
and DATEDIFF(ss, LastRunTime, GETDATE()) < @ThresholdSeconds
The first filter in the WHERE clause filters our reports that are either refreshing now or last refreshed successfully. The second allows you to use a variable to exclude a path (we keep our retired reports in a hidden folder and didn’t want them triggering an alert) – this is optional. The third filter only returns reports that failed within the last X seconds – this should match how often the job runs to check for new failures so that it’s only getting failures since the last execution. A more advanced version could check to see when the SQL Agent job last ran and get failures since then, but that wasn’t needed in our case.
There’s also a column called DataRefreshURL for each report – this will link directly to the “Scheduled Refresh” settings page for the report, and uses the report management page under (yourserver)/reports/manage/catalogitem/listcaching_pbi/(yourreport). This will allow you to go right from the email to the page that lets you view error details and refresh the report again if the error is temporary.
Create the email notification text
Now that we have a temp table (#WorkingTable) that’s holding our failed reports, let’s build an email!
I wanted to line things up neatly in columns, so the first step was figuring out how wide each column should be:
SET @LongestName = (SELECT MAX(LEN(Name)) FROM #workingtable)
SET @LongestPath = (SELECT MAX(LEN(path)) FROM #workingtable)
set @LongestLink = (SELECT MAX(LEN(DataRefreshURL)) FROM #workingtable)
With those lengths set, we can build the headers. For each of the three columns, we’ll include the column title and then enough spaces to justify each column evenly – we’ll use the same formula for the detail lines as we will for the header:
This uses both SPACE and REPLICATE to include a certain number of characters to ensure the final text is evenly column justified. There’s also an @CRLF variable that’s set at the beginning of the script – whenever I’m building multi-line text, I always create this variable as it makes breaking lines apart much, much easier further down and allows you to keep formatting consistent.
The line items are built much the same way, though here’s another handy trick that may be new to you. In the SELECT below, the @Body variable is getting appended by every single row in the resultset – the product of this is a variable that contains one additional line for every report in our table. This is also useful when you want to create a variable that contains everything in a set from a table – not just when building multi-line text, but you can consolidate anything from a list to a variable.
SELECT @Body = @Body + Name + SPACE(@LongestName - LEN(Name) + 2)
+ Path + SPACE(@LongestPath - LEN(Path) + 2)
+ DataRefreshURL
+ @CRLF
FROM #workingtable
ORDER BY Name, Path
We’re also padding these values based on the “Longest” variables we set earlier – the result is something that looks like this:
At the end, I encourage you to add a line that includes the server that’s sending the email and, if applicable, a link to any documentation – I’ve gotten into a situation before where we were getting an alert every few minutes that was being generated by some T-SQL code somewhere and we had to go through every job on every one of dozens of servers to find it. We eventually resolved the cause, but not before we’d gotten over 1000 emails each about how it was broken! Here’s something simple:
SET @Body = @Body + 'This email was generated by ' + @@SERVERNAME + ' at ' + CONVERT(VARCHAR, GETDATE(), 120)
Actually send the email
This part is simple and uses the sp_send_dbmail system stored procedure. It’s pretty straightforward – everything you need is defined in a variable earlier in the script, so you just need to call the SP:
Since you’ll be running this code from a SQL Agent job, make sure that the account you’re using for SQL Agent (or the proxy account if you’re configured one) has this permission granted. From the Microsoft docs about sp_send_dbmail:
Execute permissions for sp_send_dbmail default to all members of the DatabaseMailUser database role in the msdb database.
If you don’t have those permissions, you’ll get a moderately cryptic error and your mail won’t send.
For the “Steps Tab” from that walk-through, you’ll want to paste the script you’ve set up (once you update all the variables to match your environment). For the “Schedules Tab” step, set the job to run every X seconds, where X is the same number of seconds you set in your variables (the default in the script is 300 seconds, or 5 minutes). The notification/alerts are optional, but you can set those up if you like.
Cool – so what do I need to do?
To use the script, the minimum you need to do is set the variables at the beginning to match your environment and then schedule the agent job. Here’s the default variable block from the script:
Here’s what these are used for and when you should make changes:
@ThresholdSeconds. This is how far back you want to check for report failures. This setting should match how often you run the SQL Agent job – if they values don’t match, then you run the risk of missing some failed reports.
@ToAddresses. A list of people you want to email that should probably do somethign about this, separated by semi-colons.
@CopyAddresses. Like To, but more of a heads up – leave this NULL if not applicable.
@Blind_Copy_Recipients. We include this so we can send an email to our team’s slack channel using email integration, but we don’t want this email address to get out to anybody that gets copied. Normally NULL, but some may have a special need like this.
@URLRootDataRefresh. This should be the root of your Power BI Server address, including the “/reports” at the end. If you visit this URL, you should be redirected to the root of your reporting site to browse reports. This URL is appended with the location of the subscription settings so you can browse directly to the details of a failure.
@IgnorePath. We had a folder where we store offline reports – failures here should be ignored. If you have multiple folders like this, you can modify this variable to add them or you can modify the query in the script to exclude these folders explicitly.
@DBMailProfile. The name of the profile for sending mail. If you haven’t set up DB Mail, refer to the documentation to get this set up and name your profile. Here another good walk-through.
@Subject. Make this sufficiently scary so that recipients pay attention!
@SendMail. This is set up so you can test, and it’s defaulted to 0 (meaning the script will print your mail body rather than sending it). Once you’re happy with your settings, change this to 1 so the mail actually gets sent.
Feel free to add a comment below – I’ll update this code as people make suggestions or it improves through my own experience using it, and I hope it helps some others who miss this functionality in Power BI Server. Share below if you end up using it – I’d love to hear about it!
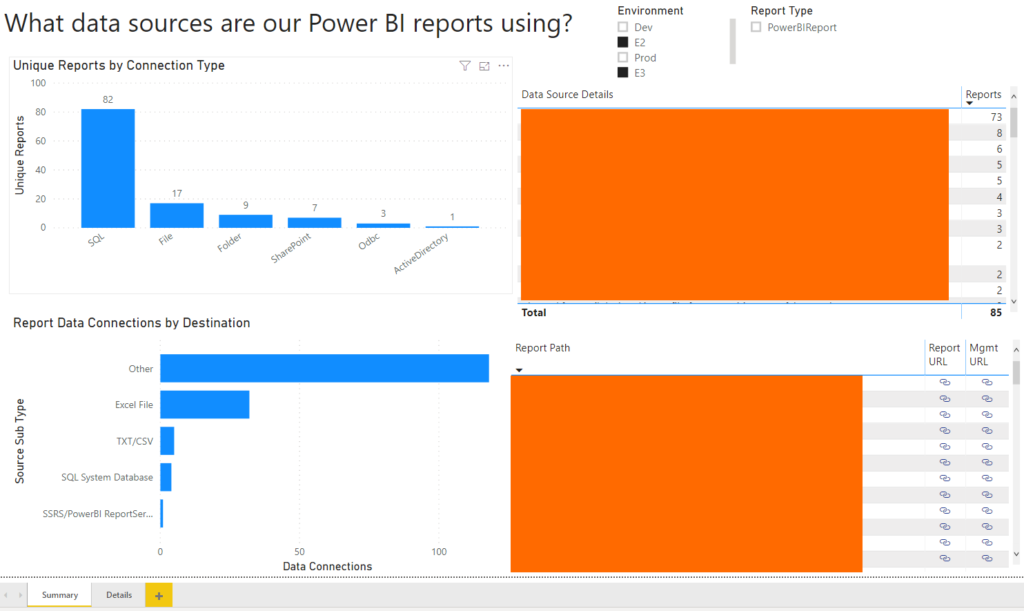
In changing our reports to point from an older database server to a newer one, we needed a way to tell which reports we’d migrated so far and which ones still had data connections to the old server. Keeping a list of reports would be the easiest way to do this, but why do that when you can write a query to track it for you!
I came across this post that provides the outline of what I was looking for:
It provided the following M-code, which uses the Power BI API to fetch a list of all reports on the server and all the datasource details (it doesn’t fetch the contents of the actual M-code behind the data sources – that would be pretty amazing). Nonetheless, pretty neat on its own (you need to replace “<YOUR URL>” in a couple of spots):
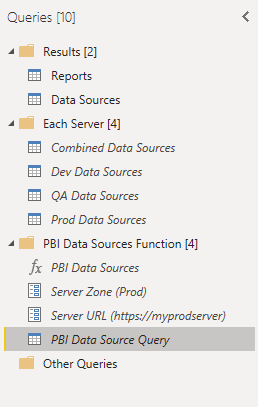
This was a good framework, but I wanted to add a few things and combine multiple different servers together (My example shows a dev, qa, and prod server being combined, but they could be any number of servers or even both Power BI Server and SSRS if you wanted):
The M-code shown earlier became the highlighted item above – I converted it to a function (“PBI Data Sources” at the top of the “PBI Data Sources Function” group) that accepted both a “Server URL” (replacing the “<YOUR URL>” portion in the initial query) and a “Server Zone” allowing you to name the server in the results. Once you have the function, we move up to the last three objects in “Each Server”, which each call the function with different parameters (for each of my server zones), and then combine them into a single dataset (“Combined Data Sources”). Finally, the results are split into a list of Reports and a list of Data Sources that you can pull into your Power BI model.
Once of the issues I ran into was that I didn’t have access to all the reports on my server – those broke my dataset with the following message:
DataSource.Error: ODate Request failed: The remote server returned an error (500) Internal Server Error
Interestingly, it wasn’t a “Permission Denied” error, but a 500 server error. I got around it by adding some code to drop any rows where I received an error by using the “try otherwise” error handing in M, something I’d never used before:
= Table.SelectRows(#"Sorted Rows", each ((try [DataSources]{0}[Id] otherwise null) <> null))
This code checks to see if it can view the very first value within the “DataSources” field, and if it can’t, it returns null and then the row gets filtered. This isn’t the most elegant way to do this – it drops any reports I don’t have access too, rather than calling them out, but it got the job done and allowed my dataset to move forward without errors.
Once the data is in the model, you can use some simple visualizations to see what types of connections you have, where you’re connecting, and what user those connections are set up to use (so you can see if every one of your connections is using the correct proxy users).
I hope this helps you get a handle on all the data sources you’re using, and make sure that everything is using the correct settings. I’ve included the empty PBIT file at the end of this post for anybody that wants to connect to their data and see what it looks like (when you open the file, it prompts you for two variables – you can put whatever you want there, but it’s because I’ve left the source query in the file).
If you do end up using this to create something, please let me know what as I’d love to see it in action!