After updating from the May 2020 release of Power BI Report Server to the January 2021 release, we started to receive this error during our report refresh schedules:
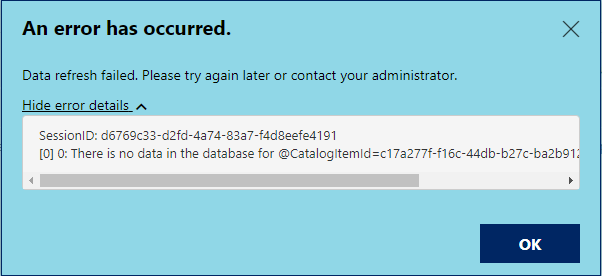
This was happening when multiple reports were refreshing at once, during our overnight schedules, as well as when multiple reports were manually refreshed at the same time. I found a post that seemed to confirm this (https://community.powerbi.com/t5/Report-Server/Scheduled-Refresh-error-quot-There-is-no-data-in-the-database/m-p/1505277) and suggested that you change your schedules so multiple reports don’t refresh at once – since were using shared schedules (including a schedule that we trigger via the API when our ETL finishes), that wasn’t an option for us.
To work around it, we had to refresh our reports one at a time, waiting until the currently one had completed before starting the next one – if you started the next one before the previous was complete, it seemed like about a 50/50 chance that the second report would fail with this error. This left a 0% chance that the overnight schedules that were attached to dozens of reports would even refresh 2-3 successfully.
I came across a post in the Power BI Community forum (https://community.powerbi.com/t5/Report-Server/There-is-no-data-in-the-database-for-catalogitemid/m-p/1721489) where somebody shared that it was caused by a code change to the code that loads the data model from the SQL database in the October 2020 release – switching a query hint in a Stored Procedure (GetCatalogExtendedContentData) from READPAST to NOWAIT (it was even annotated with a comment from the PBIRS developer that made it – nice work, whoever this was! This is a great example of a comment that has the “Why” and not the “What”, so it’s actually useful):
FROM [CatalogItemExtendedContent] WITH (NOWAIT) -- DevNote: Using NOWAIT here because for large models the row might be locked for long durations. Fail fast and let the client retry.
You can read more about query hints in the Microsoft Docs, but at a high level, READPAST (the previous code) causes a query to skip past and locked rows as if they’re not even in the table – NOWAIT, however, causes a query to fail with a lock timeout error as soon as it encounters any locked rows that it wants to read. The code change results in a failure any time we attempted to refresh a report while a previous refresh has any data model contents locked.
I couldn’t force this error to happen to one of our test environments, no matter how many reports I refreshed at once or large the data models were – given this, I wasn’t sure that fixing this code would resolve our error since the test environment had the code with the NOWAIT hint. I wanted to be sure, so I ran a SQL Profiler trace while refreshing some reports in production so I could see the error happen (WARNING – Profiler in production is usually a bad idea as it drags down performance, so proceed with caution here). Here were the three lines I saw that confirmed it:

This was exactly where the forum said the code had changed – I was seeing the stored procedure throw an immediate Lock Timeout, which was the confirmation that I needed. I ran the following script with SQL Management Studio in the Power BI Report Server database to revert the code to the May 2020 query hint (red is the code I commented out and blue is the code I added):
USE [PBIReportServer]
GO
ALTER PROCEDURE [dbo].[GetCatalogExtendedContentData]
@CatalogItemID UNIQUEIDENTIFIER,
@ContentType VARCHAR(50)
AS
BEGIN
SELECT
DATALENGTH([Content]) AS ContentLength,
[Content]
FROM
[CatalogItemExtendedContent] WITH (READPAST) -- Reverting this back to May 2020 code. Commented line below is original in January 2021 version.
-- [CatalogItemExtendedContent] WITH (NOWAIT) -- DevNote: Using NOWAIT here because for large models the row might be locked for long durations. Fail fast and let the client retry.
WHERE
[ItemID] = @CatalogItemID AND ContentType = @ContentType
END
GOWith this change deployed, we didn’t have a single report refresh failure over the weekend when our shared schedules ran! I’m not sure why I couldn’t force the issue in our lower environments, though I suspect it has something to do with either lower total data model size stored there, or index maintenance, or something else related to the data storage. I checked and all the SQL Server settings I could see where the same (as they should be) so I can’t confirm what additional situation causes this error (since clearly it doesn’t happen in every installation).
If you are able to use this successfully or have issues, please weigh in on the community post above or in the comments below!